
Accurate three-dimensional (3D) human motion tracking is essential for immersive augmented reality (AR) and virtual reality (VR) applications, allowing users to engage with virtual environments through realistic full-body avatars. Achieving this level of detail, however, is challenging when the driving signals are sparse, typically coming only from upper-body sensors, such as head-mounted devices and hand controllers.
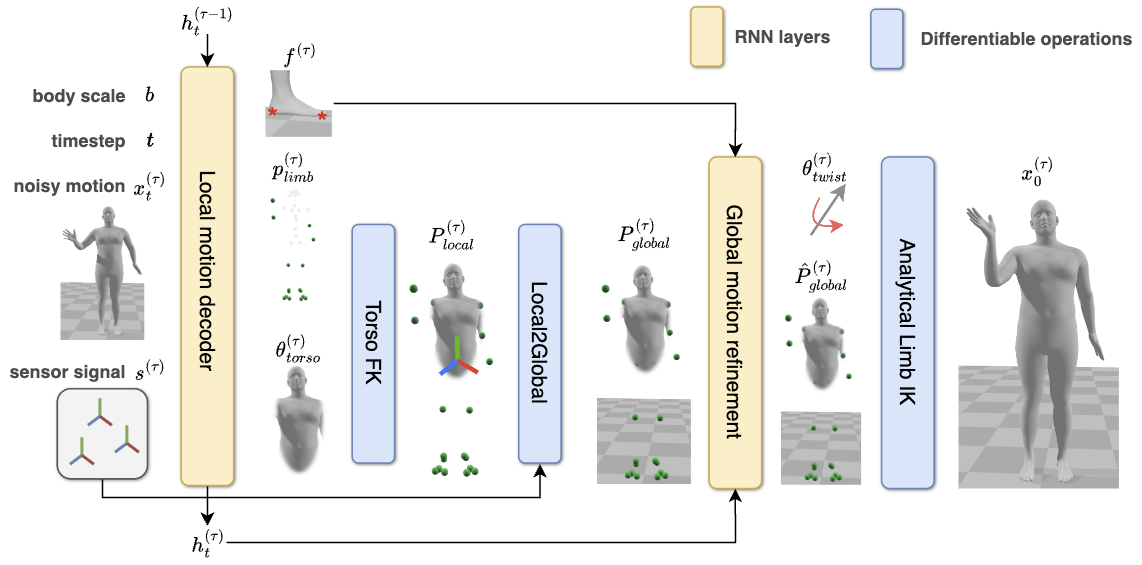
To address this challenge, we propose EgoMDM (Egocentric Motion Diffusion Model), an end-to-end diffusion-based framework designed to reconstruct full-body motion from sparse tracking signals. EgoMDM models human motion in a conditional autoregressive manner using a unidirectional recurrent neural network, making it well-suited for real-time applications.
By embedding local-to-global translation, forward and inverse kinematics, and foot-contact detection within the diffusion framework, EgoMDM achieves seamless, end-to-end motion synthesis, effectively reducing artifacts like foot sliding and ground penetration. Additionally, EgoMDM is conditioned on the user's body scale, allowing it to generalize across a diverse population and produce consistent avatar shapes over time. In our extensive experiments on the AMASS motion capture dataset, EgoMDM achieves state-of-the-art performance in both motion tracking accuracy and synthesis quality, demonstrating its robustness and adaptability across various human motion scenarios. Furthermore, EgoMDM significantly outperforms the existing models when tested on the real signal inputs, highlighting its robustness and applicability to the real-world data.
Given the tracking signals of the headset and two hand controllers, we first denoise the partially represented motion and construct the full-body motion using an analytical IK solver. The denoiser network first estimates the foot-ground contact probability, limb joint twists and positions, and torso joint angles. Followed by local-to-global translation, we construct the initial global-space human motion using a residual refinement network to update motion. Finally, full-body mesh motion is analytically computed.
A comparison of motion-tracking accuracy between HMD-Poser and EgoMDM (ours). Ground-truth is derived from the AMASS mocap dataset. Vertices are colored differently based on the per-vertex distance to the ground-truth motion (red indicates worse performance). The motion synthesized by EgoMDM shows larger similarity to the reference ground-truth motion than the state-of-the-art method in various movement scenarios.

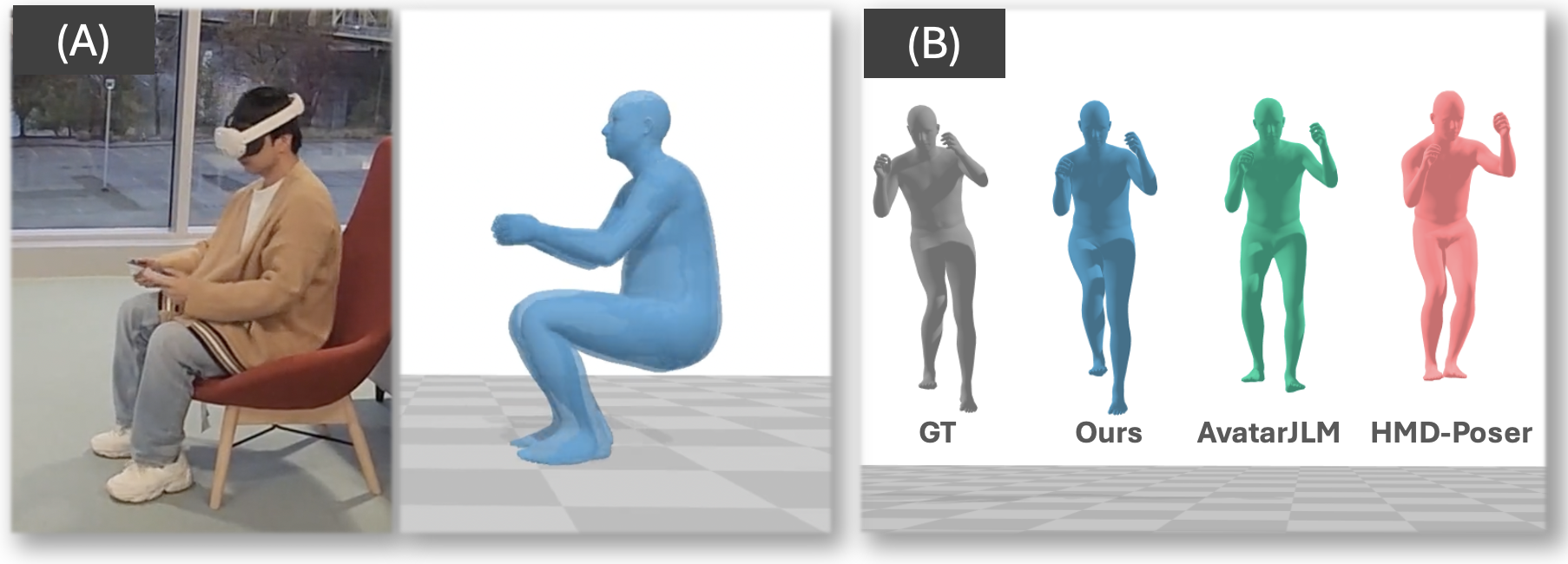
A comparison of motion-synthesis quality between AvatarJLM, HMD-Poser, and EgoMDM (ours). EgoMDM shows less foot skating (first row), floating (second row), and floor penetration (third row) compared to the other methods.
Our model demonstrates robust performance even on challenging scenarios such as uneven terrain, showcasing its adaptability beyond flat ground-plane assumptions.
@inproceedings{shin2026egomdm,
author = {Shin, Soyong and Pahuja, Anuj and Richard, Alexander and Kitani, Kris and Saragih, Jason and Chen, Yuhua and Xu, Weipeng and Halilaj, Eni and Bagautdinov, Timur},
title = {EgoMDM: Diffusion-based Human Motion Synthesis from Sparse Egocentric Sensors},
booktitle = {International Conference on 3D Vision (3DV)},
year = {2026},
}